随着AI技术的不断发展,加州大学圣克鲁兹分校的研究揭示了AI模型变得“笨拙”的新原因。研究者们将焦点放在了“任务污染”问题上,指出大型模型在训练过程中接触了大量任务示例,给人一种AI拥有零样本或少样本能力的错误印象。本文将探讨这一现象的具体原因以及对AI发展的挑战。

随着加州大学圣克鲁兹分校的一项新研究的出现,我们对于为什么一些AI模型在训练后变得“笨拙”有了新的解释。研究聚焦在了“任务污染”问题上,这一问题指的是在训练时期,大型模型见识了大量任务示例,导致AI在零样本或少样本情况下的表现与训练前不同。
论文特别强调了一个被忽视的问题,即当人们仅仅关注模型在训练截止之前的任务上的表现时,大型模型似乎表现得更出色。这一现象可能给人一种AI在各种任务上都能轻松胜任的错觉。
研究团队认为,问题的关键在于大型模型在训练后参数冻结,而人们不断提出新的任务,导致输入分布不断变化。如果模型不能适应这种变化,就会表现出能力慢慢退化的趋势。此外,研究人员指出,人们往往误以为提出一个新问题AI就能回答,实际上是因为模型在训练时已经见过大多数常见任务。
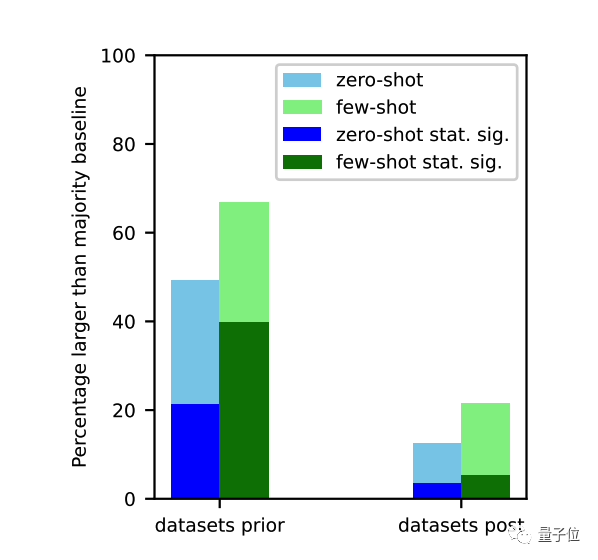
针对这一现象,研究团队评估了12种模型,包括ChatGPT之前的GPT-3系列、OPT、Bloom,以及最新的GPT-3.5-turbo、羊驼家族(Llama、Alpaca和Vicuna)等。结果显示,这些模型在训练截止之前的任务上表现更好,突显了“任务污染”问题的普遍性。
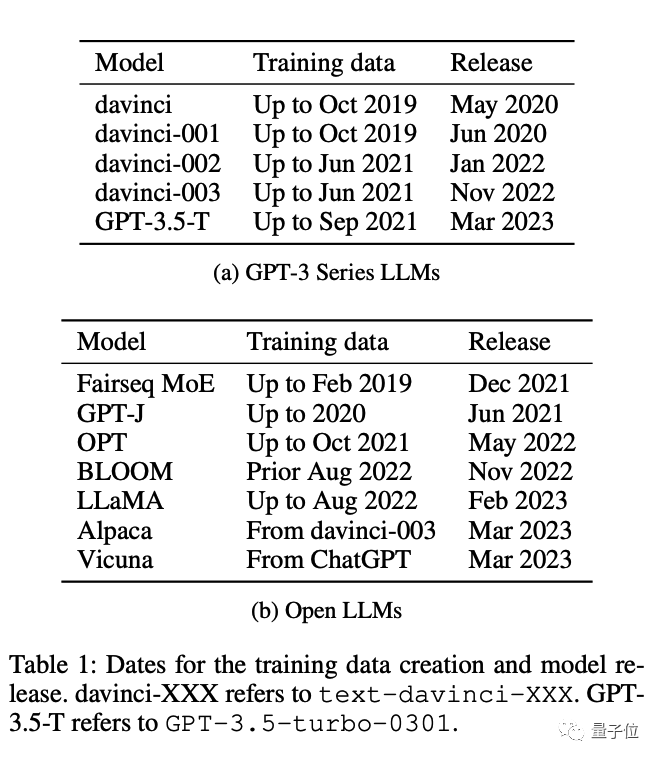
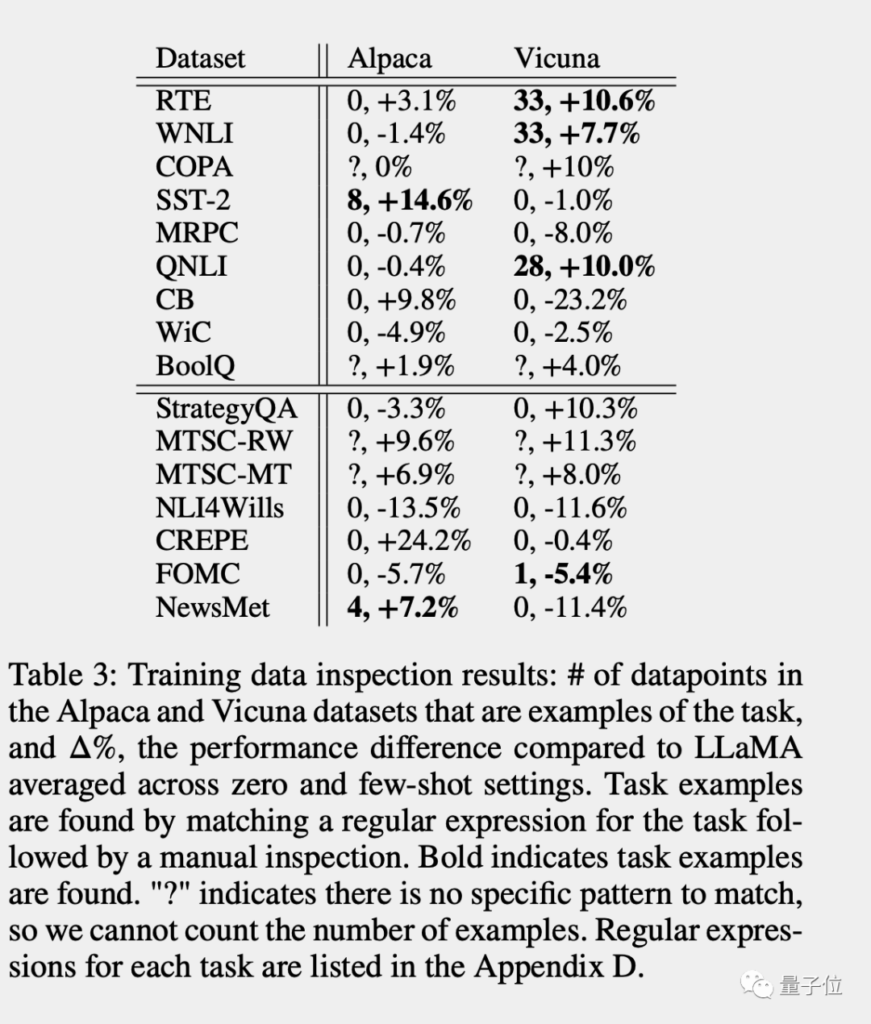
为了测量任务污染的程度,研究团队采用了四种方法:检查训练数据、提取任务示例、成员推断和按时间顺序分析。这些方法揭示了任务污染的存在,尽管其程度仍不清楚。对于这一问题,研究团队呼吁更多的模型开源其训练数据,以便更深入地检查任务污染问题。
研究的结论指出,由于任务污染,闭源模型在零样本或少样本评估中可能呈现比实际更好的表现,尤其是经过RLHF微调的模型。对于未来的发展,团队建议采取谨慎态度,并呼吁更多模型开源其训练数据以促进透明度。
这一研究引起了关于AI发展中持续学习难题的深刻思考。人们对于AI是否能够持续适应变化的讨论将成为未来研究的重要议题。
本文来自投稿,不代表TePhone特锋手机网立场,如若转载,请注明出处:https://www.tephone.com/article/3126
