随着科技的不断进步,GPT-4作为目前最强大的通用语言模型,尽管在多项任务上表现出色,但在抽象推理方面与人类水平存在较大差距。圣达菲研究所的最新研究揭示了这一差距,挑战了GPT-4作为通用人工智能(AGI)的未来发展。

近期,圣达菲研究所的科研人员通过严谨的定量研究方法发现,GPT-4在推理和抽象方面与人类水平存在较大差距。尽管GPT-4被认为是目前最强大的通用语言模型,但要实现从其水平发展出AGI,似乎还有相当长的一段路要走。
GPT-4引起了广泛的关注,一些人对其是否具备AGI的特征提出了质疑。其中,主要反对意见集中在GPT-4的有限推理能力和任务特定的泛化上。
首先,GPT-4被指责不能执行“反向推理”,并且在对世界的抽象模型进行估计方面面临困难。此外,虽然GPT-4在形式上可以进行泛化,但在跨任务的目标方面可能会遇到困难。
为了更具体地评估GPT-4在抽象推理能力方面的表现,研究人员采用了ConceptARC基准测试。这一测试基于ARC(一组手动创建的类比谜题)的基础上进行了改进,旨在更加系统性地对比人类和GPT-4在抽象推理方面的能力。

ConceptARC测试以480个任务为基础,这些任务涵盖了特定核心空间和语义概念的系统变化,如Top和Bottom、Inside和Outside、Center,以及Same和Different。每个任务以不同的方式实例化这些概念,并具有不同程度的抽象性。

结果显示,纯文本版本的GPT-4在480个任务上的表现远远不如人类。对于多模态的GPT-4V,在最简单的48个任务的视觉版本上,其性能甚至低于纯文本情况。
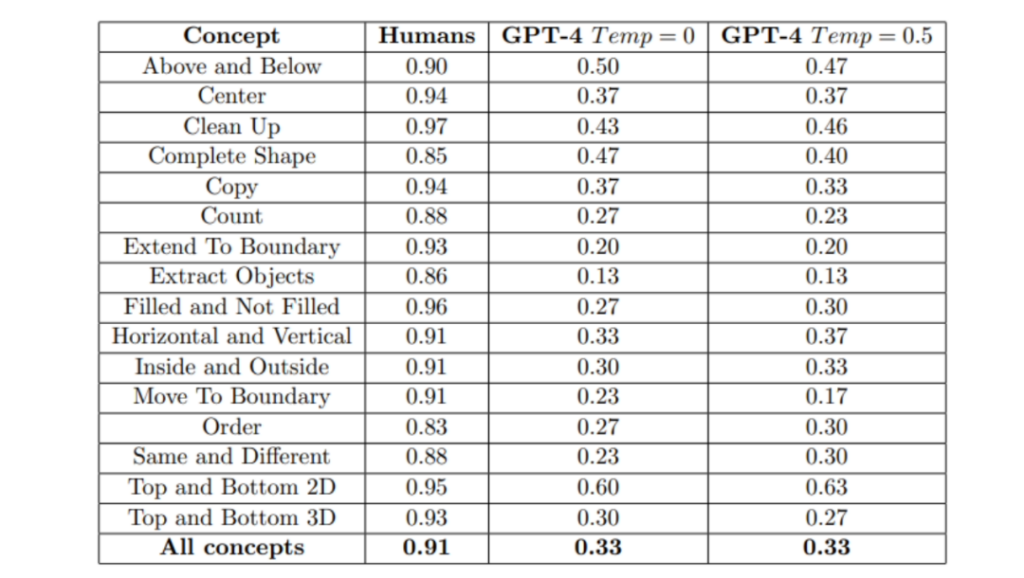
尽管GPT-4被广泛认为是目前最强大的通用语言模型,但这项研究表明,它仍然无法稳健地形成抽象并推理关于基本核心概念的内容,尤其是这些概念在其训练数据中之前未见过的上下文中。
对于GPT-4和GPT-4V在抽象推理能力上的提升,研究人员表示可能需要通过其他提示或任务表示方法来实现。这一研究的结果引发了对大型语言模型是否能够完全达到人类水平的深刻思考,显示出在实现AGI方面,我们仍然面临着巨大的挑战和未知。
本文来自投稿,不代表TePhone特锋手机网立场,如若转载,请注明出处:https://www.tephone.com/article/3113
