在2024年的世界移动通信大会上,高通正在为其骁龙系列芯片为安卓手机提供的AI功能增添更多特色。该芯片制造商已经展示了一些令人印象深刻的AI功能,例如语音激活的媒体编辑、使用稳定扩散技术进行设备端图像生成,以及构建在Meta等公司大语言模型之上的更智能的虚拟助手。

今天,公司为这些AI超级功能增加了更多实力。首先是在智能手机上运行大型语言与视觉助手(LLaVa)的能力。可以将其视为像ChatGPT这样的聊天机器人,具有Google Lens的功能。因此,高通的解决方案不仅可以接受文本输入,还可以处理图像。
例如,您可以上传一张描述冷盘的图片并提出基于该图片的问题。基于一个可以处理超过70亿个参数的大型多模型模型(LMM),该AI助手将告诉您图片中所示冷盘上的各种水果、奶酪、肉类和坚果的种类。
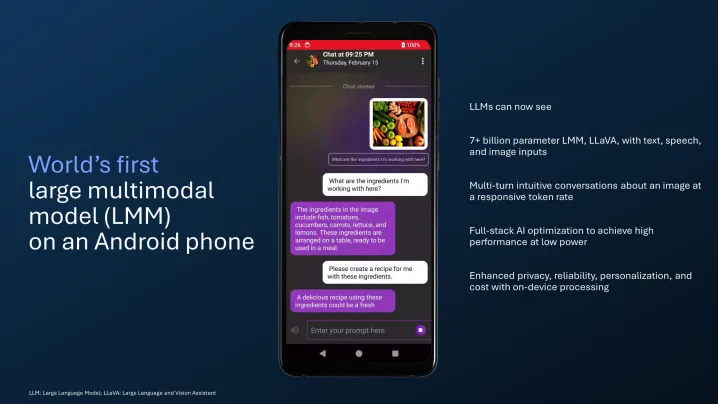
它还可以处理后续查询,因此您可以进行连续的对话。现在,像ChatGPT和Copilot这样的产品也已经具备了多模态能力,这意味着OpenAI的工具也可以处理图像输入。然而,这里有一个关键的区别。
像ChatGPT和Copilot这样的产品仍然非常依赖云架构,这意味着您的数据是在远程服务器上处理的。高通的推动方向是在设备上进行处理。一切都在您的手机上进行,这意味着整个过程更快,且几乎没有隐私侵入的风险。
“这个LMM在设备上以响应速度运行,从而提高了隐私、可靠性、个性化和成本效益,”高通表示。高通承诺的基于LLaVa的虚拟助手是否会作为独立应用程序推出,或者是否会收取费用,目前尚未正式确认。
接下来,高通的另一个声明涉及到图像生成和处理的创意领域。不久前,高通演示了使用稳定扩散技术在手机上进行世界上最快的文本到图像生成。今天,公司首次展示了LoRA驱动的图像生成的初步效果。
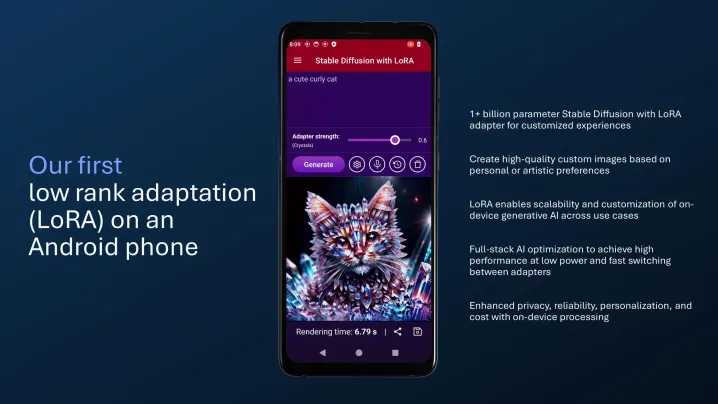
LoRA采用了与常规生成式AI工具(如DALL·E)不同的方法来生成图像。LoRA,即低秩适应,是由微软开发的一种技术。训练AI模型可能成本高昂,延迟高,并且在硬件方面要求特别严格。
LoRA的作用是大幅减少模型的重量,这一目标通过仅关注模型的特定部分并减少用于训练的参数数量来实现。通过这样做,内存需求降低,处理速度加快,而且调整文本到图像模型所需的时间和精力也大大减少。
随着时间的推移,LoRA提炼技术已被应用于稳定扩散模型,用于根据文本提示生成图像。由于LoRA模型的效率提高和易于适应性,它被视为适合智能手机的定制路线。高通显然也这么认为,即使竞争对手联发科也采纳了相同的解决方案,用于其旗舰Dimensity 9300芯片的生成式AI技巧。
高通还在MWC 2024上展示了一些其他AI技巧,其中一些已经出现在三星Galaxy S24 Ultra上。其中包括使用生成式AI填充扩展图像的画布的能力以及使用AI动力生成视频。后者是非常有雄心的,特别是在看到OpenAI用Sora取得的成就之后。值得关注的是,看看高通如何将其移植到智能手机上。
本文来自投稿,不代表TePhone特锋手机网立场,如若转载,请注明出处:https://www.tephone.com/article/12059
